I want to change that by writing and releasing a set of scripts to search for specific types of logs, written on top of python3 and maintained against the latest version of the Google API, using the "readonly" scopes provided by Google. My goal is to have a starting point for SecOps teams, a place where they can see how to get rolling with the API and then build off of my starter scripts to do interesting things that address the problems they face and are tailored to their environments.
Note: I stated I want to provide something small and light. There is already a *comprehensive* solution to interacting with the Google API via the command line called GAM: https://github.com/jay0lee/GAM
Prerequisites - Google Service Account
Before you go any further, you're going to need a service account or oauth2 access token for your Google domain. For most of us that will mean going to our Google admins and asking for an oauth2 credentials file. Google offers a two-week test setup if you're interested in "G Suite"/"Google Apps for Business" so I moved one of my domains and dove into their account/IAM/token tools.
I'm not going to try to document how to create a service account, that could be its own post, but more information on how to generate one can be found in the Google documentation:
After the account is created, the oauth2 token (in JSON) should look something like this:

To keep things simple, I have named mine "client_secret.json".
The three scopes that need to be authorised for the purposes of this post are:
- https://www.googleapis.com/auth/admin.reports.audit.readonly
- https://www.googleapis.com/auth/admin.reports.usage.readonly
- https://www.googleapis.com/auth/gmail.readonly
In the Google Admin interface, they should be specified on one line, separated by a comma.
Each API will require a "delegation" user -- a user on whose behalf the script is running. For the "audit" API it will probably be your account but for the "gmail" API it will need to be the user against whose account the script runs. If you have a user, foo@bar.com, and your script is getting a list of email subjects for that user, the delegation user will be "foo@bar.com".
Prerequisites - Python Modules
My API VM is a "fresh" FreeBSD 11.1 installation but it can be any system capable of running python3 - it could be FreeBSD, macOS, any modern Linux or any modern Windows. As I've noted in other posts, I just happen to like FreeBSD. I've added a user named 'demo' and they're able to issue commands via 'sudo'.
With that setup, I need to install python, pip and a few python modules. First, python and pip can be installed with
If you have a Linux background, this is the equivalent of "sudo apt install python3-pip" on Debian/Ubuntu or "sudo yum install python-pip" on RH and derivatives.
With that setup, I need to install python, pip and a few python modules. First, python and pip can be installed with
sudo pkg install py36-pip
If you have a Linux background, this is the equivalent of "sudo apt install python3-pip" on Debian/Ubuntu or "sudo yum install python-pip" on RH and derivatives.

Notice that on Linux systems, this usually provides "python3". That is typically a link to a specific 3.x version of python. FreeBSD doesn't provide the link by default so if you're installing on FreeBSD, keep that in mind. This is why it's "py36-pip" instead of something like "py3-pip". For example, on a system running Ubuntu 16.04.3 LTS, "/usr/bin/python3" is a link to "/usr/bin/python3.5".
Once python and pip are installed, it's time to install the necessary python modules. These are:
- httplib2
- oauth2client
- google-api-python-client
This is why I wanted pip - some package managers will actually have separate packages for each of these but using pip lets me stay current. Again, notice I'm calling it with "pip-3.6" instead of the "pip3" you'd see on a Linux system.
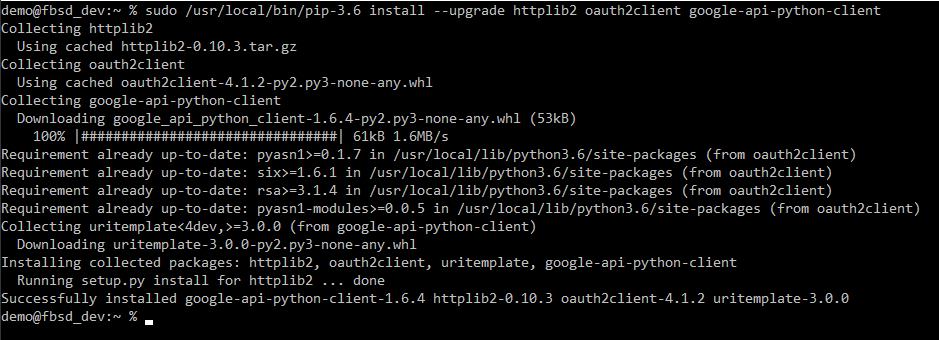
Start python from the command line with either "python3" or "python3.6" and you can interact with it directly. You can use the following as a simple "test" script to make sure your modules are installed and will work:
import httplib2
from apiclient import discovery
from oauth2client.service_account import ServiceAccountCredentials
quit()
When I did it, it looked like this:

Start Scripting
Now that python/pip/necessary modules are installed and I have my oauth2 token and delegated account name, it's time to write a small script that reads in those credentials and attempts to connect to Google. This first script is going to use the "Admin SDK" and you can read up on it here: https://developers.google.com/admin-sdk.
There is a LOT of information there so to be a little more specific, we're going to use the "reports" API. You can read more about that here: https://developers.google.com/admin-sdk/reports/v1/get-start/getting-started
If you want to dive straight into some of their more technical documentation, I do find the API reference for the Admin SDK to be quite good in some ways and it can be found here: https://developers.google.com/admin-sdk/reports/v1/reference
With that bit of "light reading" provided, let's start on a "first script". This will:
- import the required modules
- attempt to read the oauth2 token file (remember, mine is "client_secret.json")
- attempt to set the necessary scopes (I listed them above)
- attempt to create delegated access (this means the script will act on behalf of an actual account)
- attempt to build an "admin"/"reports_v1" API object
- attempt to authorise that object with Google
In code, this would look like:
import httplib2
from apiclient import discovery
from oauth2client.service_account import ServiceAccountCredentials
oauth2_file = "client_secret.json"
oauth2_acct = "my-account@my-company.com"
oauth2_scopes = ['https://www.googleapis.com/auth/admin.reports.audit.readonly',
'https://www.googleapis.com/auth/admin.reports.usage.readonly']
sa_creds = ServiceAccountCredentials.from_json_keyfile_name(oauth2_file, oauth2_scopes)
delegated = sa_creds.create_delegated(oauth2_acct)
http_auth = delegated.authorize(httplib2.Http())
service = discovery.build('admin', 'reports_v1', http=http_auth)
exit()
If I save it as "test_script.py", run it with "python3.6 test_script.py" and get no output, I know it works (and indeed it does for me).


The next thing I'm going to do is move the oauth2_ variables to another file called "api_info.py". Instead of using, for example, "oauth2_file", I would have "import api_info" and then use that value with "api_info.oauth2_file". In the long run it's going to save time and effort because I'm going to have several scripts all using the same credential information and if I change the scope, change the account, etc., I only have to change it in one place. With that change, my "test_script.py" now looks like:

Authentication Logs
Now that I have a starting point, I want to make my script do something useful. If you're going to start pulling logs from Google and put them into your SIEM (which should ultimately be the goal...), I would recommend starting with the login logs. This gives you really good data like:
- who logged in/out
- at what time
- from which IP address
- success or failure
If you're correlating other authentication logs, this is a great addition for correlation. Don't be afraid of volume here - in my day job we have approximately 20,000 users and the Google login logs are typically just a few megabytes per day. I know of organisations with tens of thousands of users and they have 50GB/day Splunk licenses, they make sure they get their Google authentication logs.
When you query the "reports_v1" API, Google provides a list of "activities". Each activity is a JSON object. Those fields are documented here: https://developers.google.com/admin-sdk/reports/v1/reference/activities/list
This is a sample failed login for one of my domains:

At 17.03 UTC on 28th of December, someone at the IP address 1.2.3.4 tried to login to Google using "a.user@my-domain.com" as the username and it failed due to an invalid password. Yes, I edited the *content* of the fields for demonstration purposes but each successful and unsuccessful login will have each of those fields with the appropriate values. That object will come all on one line, though, so it can be a bit difficult to read.
Getting the Authentication Logs
Now it's time to work on the script so it retrieves and displays authentication logs in a meaningful way!
From the API documentation, I know that I need to call activities().list().execute(), and I know I need to give it two parameters:
- applicationName - this will be 'login'
- userKey - this is a specific FULL email address in your domain OR you can use the keyword 'all'
From the above screenshot, I also know that I'm going to get a bunch of JSON objects that have ['id']['time'], ['actor']['email'] and ['ipAddress'] fields, so I know I can look specifically for those. I also know ['events'][0]['name'] is going to tell me where it was a login_success, login_failure or logout, so I want that as well.
Adding that information to my script, I know have:
import api_info
import httplib2
from apiclient import discovery
from oauth2client.service_account import ServiceAccountCredentials
sa_creds = ServiceAccountCredentials.from_json_keyfile_name(api_info.oauth2_file, api_info.oauth2_scope)
delegated = sa_creds.create_delegated(api_info.oauth2_email)
http_auth = delegated.authorize(httplib2.Http())
service = discovery.build('admin', 'reports_v1', http=http_auth)
results = service.activities().list(userKey='all', applicationName='login').execute()
activities = results.get('items', [])
for activity in activities:
print()
print("New login record")
print("Time: " + activity['id']['time'])
print("Email Address: " + activity['actor']['email'])
print("IP Address: " + activity['ipAddress'])
print("Event result: " + activity['events'][0]['name'])
exit()
Since I'm doing something specific, I'm going to go ahead and save this version as "get_logins.py".
When it runs, I'll get a list of the first 1000 login successes and failures for all users in my domain for UP TO the last 180 days. The 1000 limit is easy to address but it's beyond the scope of this post; I'll provide a github link at the end that has a version of this script with it included. For example, this is an (edited) sample of what I get for an account I've only used from one location:

If I wanted to search for JUST logs for "test.acct@my-domain.com", I'd use that as the userKey value instead of 'all' and my results would be identical.
IR-driven Scripting
Since most of my work is incident response driven, let's have a wee scenario. An attacker phishes a set of credentials and logs into someone's email. At that point they decide to launch a spear-phishing campaign against select members of your management but they want any responses to be invisible to the person actually uses the account - maybe they add a filter that automatically sends those emails to the Bin. It's 2 AM and the SOC analyst on-call, Lexi, gets a support ticket from the CFO saying, "this is Janet, the CFO. I just received an odd email from Steve in HR saying he has an emergency purchase that needs approval tomorrow but the file he sent me won't open! the subject is 'emergency purchase'." The analyst takes a closer look and sees it was actually submitted at 9PM the night before but they're just now receiving it.
Okay, let's walk through this. It's 2.00 AM so calling Janet is a Really Bad Idea. You don't call C-levels in the middle of the night unless they've JUST contacted you. Angry spouses, upset babies, waking up a C-level, these are all resume-generating events. Your analyst probably isn't a Google "superadmin" so they can't check the actual email log to get information about the emails sent from Steve to Janet. For the sake of argument let's say you aren't using Vault or some other archival tool because <pick a reason>. What does Lexi do?
As it turns out, there are a host of tools available to her via the "gmail" API. Google's documentation for it is here:
https://developers.google.com/gmail/api/guides/
and the API reference is available here:
https://developers.google.com/gmail/api/v1/reference/
One simple thing to do would be to search Janet's email for any messages from Steve with a subject of "emergency purchase". From the above reference, I know the API lets me retrieve a list of message IDs that match a query filter and that I can then use that message ID field to retrieve actual emails; additionally, I know that I can use ['payload']['headers'] to get the message headers (like "From", "To", "Subject", etc) and I know there is a ['snippet'] field that has a short, plain-text version of the email. With that knowledge, I can write something like the following:
import api_info
import httplib2
from apiclient import discovery
from oauth2client.service_account import ServiceAccountCredentials
query = 'subject: "emergency purchase'
userID = 'cfo.janet@my-company.com'
sa_creds = ServiceAccountCredentials.from_json_keyfile_name(api_info.oauth2_file, api_info.oauth2_scope)
delegated = sa_creds.create_delegated(userID)
http_auth = delegated.authorize(httplib2.Http())
service = discovery.build('gmail', 'v1', http=http_auth)
query = 'subject: "emergency purchase'
userID = 'cfo.janet@my-company.com'
results = service.users().messages().list(userId=userID, q=query).execute()
messages = results.get('messages', [])
for aMessage in messages:
mid = aMessage['id']
msgObject = service.users().messages().get(userId=userID,id=mid).execute()
for aHeader in msgObject['payload']['headers']:
if aHeader['name'] == "To":
print("Recipient is: " + aHeader['value'])
elif aHeader['name'] == "From":
print("Sender is: " + aHeader['value'])
elif aHeader['name'] == "Subject":
print("Subject is: " + aHeader['value'])
elif aHeader['name'] == "Message-ID":
print("Message ID is: " + aHeader['value'])
print("Snippet from email: ")
snippet = msgObject['snippet']
print(snippet)
print()
exit()
NOTE: the gmail.readonly, gmail.modify or https://mail.google.com/ scopes must be allowed for this to work. I HIGHLY recommend using the gmail.readonly scope unless you want your SecOps team to have the ability to delete emails (which you may do once they're adept at finding the message IDs of phishing messages).
If Lexi had such a script, named 'get_headers.py', and were to run it, she may get something like this:

Using the same API, she could go further and retrieve the actual attachment.
What if the email HAD come from Steve's proper account, though? At this point Lexi could use get_logins.py to see which IPs had accessed Steve's account and then look for additional accounts being accessed from the same address. She could then possibly find other malicious/phishing emails that were sent and, if allowed the .modify scope, delete them from user mailboxes before the user ever sees them.
Wrapping Up
The Google/G Suite API offers a fantastic opportunity for incident responders and SecOps teams to have visibility into their email and collaboration environment. It not only allows us to pull information in an easily-parsed format (json) for one-off searches but also to pull logs in volume to import into our (hopefully) much faster and more powerful SIEMs. With a little bit of tuning, any of the scripts I've offered above can write log data in CSV, JSON or XML, with field and header names of your choosing, and they can be executed via any scheduling mechanism your operating system uses. Since this is part of a series about being a SIEM, a post in the very near future will rely on some of these scripts writing out in JSON so if you do take a look at them on github, know they are very much early versions!
As promised, they're at:
https://github.com/kevinwilcox/python-google-api
Take a look at all the other tools that are available, by all means. GAM is the de facto for managing Google domains from the CLI and should be part of everyone's toolkit...but if you're going to embed GAM into a script to do something, why not use the API directly to accomplish *exactly* what you want?